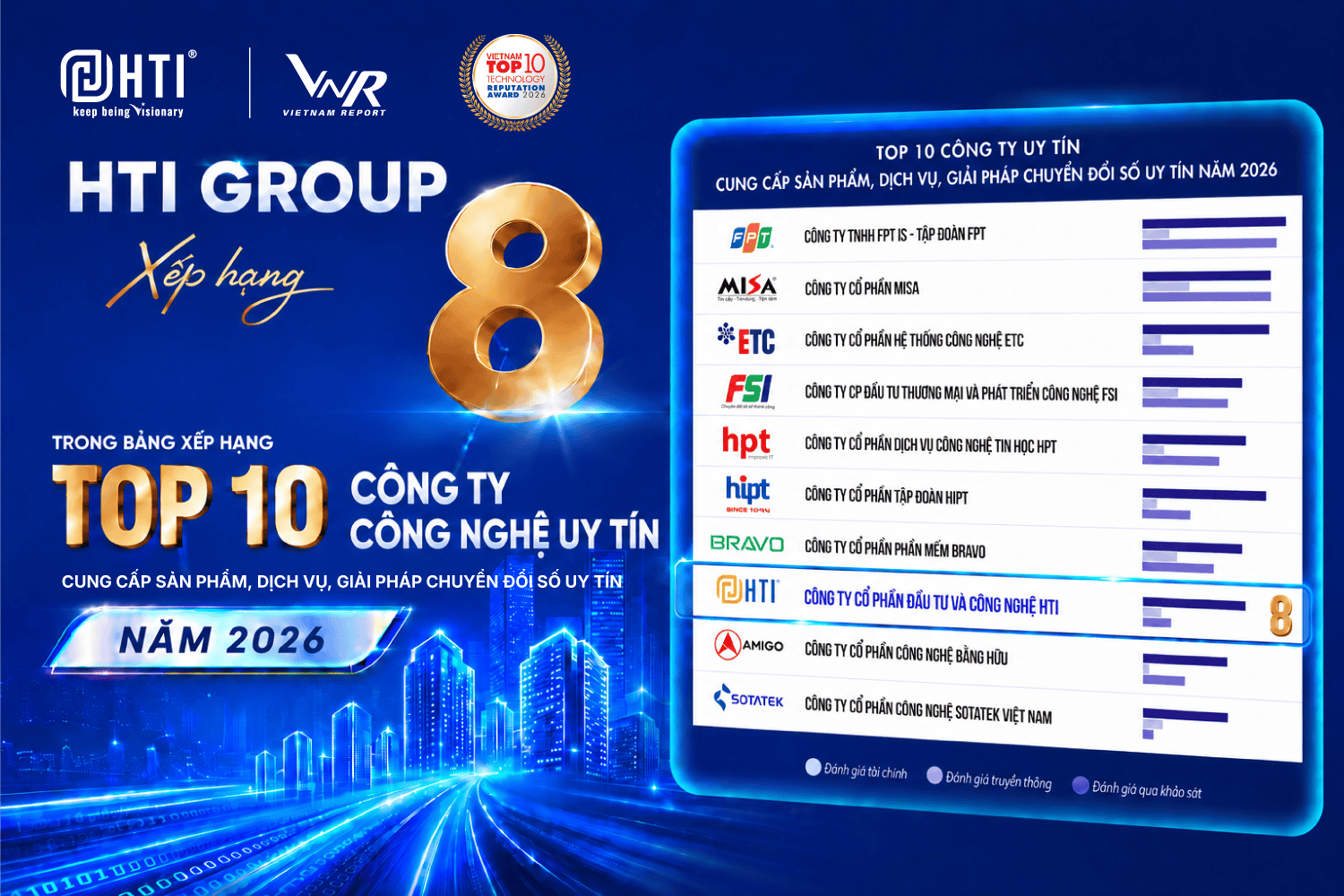
This post is also available in: Tiếng Việt (Vietnamese)
Nhận dạng giọng nói – Speaker Identification (SID)
Công nghệ nhận dạng giọng nói Phonexia sử dụng sức mạnh của kỹ thuật sinh trắc học giọng nói để nhận dạng giọng nói, xác định liệu giọng nói trong hai bản ghi thuộc về cùng một người hay hai người khác nhau. Độ chính xác cao của giải pháp nhận dạng giọng nói Phonexia, đã được xác nhận trong Đánh giá về cách mạng về nhận dạng giọng nói của Viện tiêu chuẩn và Kỹ thuật quốc gia (NIST) Hoa Kỳ.
Phạm vi ứng dụng của công nghệ nhận dạng giọng nói
Công nghệ có thể được sử dụng cho các yêu cầu về nhận dạng giọng nói khác nhau.
- Tìm kiếm người phát biểu khi hỏi về một giọng nói, giọng nói này ở đâu, khi tìm kiếm một người nói trong một kho lưu trữ lớn.
- Phát hiện giọng nói khi đang theo dõi một số lượng lớn các bản ghi hoặc luồng âm thanh và tìm kiếm sự xuất hiện của một giọng nói cụ thể.
- Phát hiện giọng nói có thể được triển khai cho mục đích cảnh báo gian lận.
- Xác minh người phát biểu, chẳng hạn khi một người gọi ngân hàng và nói, “Xin chào, tôi là Đỗ Văn T”, công nghệ sẽ nhận dạng được giọng nói này có phải là giọng nói của Đỗ Văn T không?
- Cách tiếp cận xác minh một-một (1: 1) này cũng được sử dụng trong các hệ thống Thoại-Mật khẩu, có thể tăng thêm bảo mật cho xác thực đa yếu tố qua điện thoại.
- Đặc biệt nhận dạng giọng tự động quy mô lớn cũng được các cơ quan thực thi pháp luật sử dụng thành công trong quá trình điều tra cho mục đích tìm kiếm cơ sở dữ liệu và xếp hạng nghi phạm. Trong các giai đoạn sau của một vụ án, giám định giọng nói sử dụng lượng dữ liệu nhỏ hơn và so sánh 1: 1 để đánh giá bằng chứng và để xác định danh tính của người nói và sử dụng nó tại tòa án.

Công nghệ này hoạt động như thế nào?
Công nghệ dựa trên thực tế là các cơ quan sinh học cấu thành giọng nói và thói quen nói của mỗi người ít nhiều là độc nhất. Do đó, các đặc điểm (hoặc nét đặc trưng) của tín hiệu giọng nói được ghi trong bản ghi cũng ít nhiều là duy nhất, do đó công nghệ có thể độc lập về ngôn ngữ, giọng nói, văn bản và kênh.

Hệ thống nhận dạng giọng nói tự động dựa trên việc trích xuất các các đặc điểm độc nhất từ giọng nói và sự so sánh của chúng. Do đó, các hệ thống thường bao gồm hai bước riêng biệt: Trích xuất giọng nói (đăng ký người nói) và so sánh bằng giọng nói.
Tốc độ xử lý phụ thuộc vào mô hình công nghệ và có thể nhanh hơn từ 5 đến 50 lần so với thời gian thực trên lõi CPU của một máy chủ.
Trích xuất bằng giọng nói là phần tốn nhiều thời gian nhất của quy trình. Mặt khác, tốc độ so sánh bằng giọng lại diễn ra rất nhanh – hàng triệu so sánh bằng giọng nói có thể được thực hiện chỉ trong 1 giây.
Trích xuất giọng nói (Đăng ký giọng nói)
Ghi danh giọng nói bắt đầu bằng việc trích xuất các đặc điểm âm thanh từ bản ghi của một giọng nói đã biết. Quá trình tiếp tục với việc tạo ra một mô hình giọng nói sau đó được chuyển đổi thành một biểu diễn số nhỏ nhưng có tính đại diện cao được gọi là Vết giọng nói (Voiceprint). Trong quá trình này, SID áp dụng các kỹ thuật bù kênh hiện đại. Giọng nói là một ma trận có độ dài cố định, nắm bắt các đặc điểm nhất của giọng nói của người nói.
Lượng lời nói tối thiểu được đề nghị cho việc ghi danh là khoảng. 30 giây (Phonexia SID thế hệ thứ 4 giảm yêu cầu này xuống 20 giây).

Giọng nói sau đó có thể được lưu trữ trong cơ sở dữ liệu dưới dạng tệp nhị phân có đuôi .vp. Dưới đây là một ví dụ về nội dung giọng nói ở dạng người có thể đọc được:

So sánh vết giọng nói
Bất kỳ giọng nói nào được tạo từ ít nhất 10 giây lời nói (Phonexia SID thế hệ thứ 4 giảm yêu cầu này xuống còn 7 giây) của một người nói không xác định có thể được so sánh với giọng nói đăng ký hiện có và hệ thống trả về điểm cho mỗi lần so sánh. Điểm số được tạo ra bằng cách so sánh hai giọng nói bằng cách sử dụng Phân tích phân biệt tuyến tính xác suất (PLDA).
Chấm điểm
Điểm số được tạo ra bằng cách so sánh hai giọng nói là ước tính xác suất (P), rằng chúng ta có được bằng chứng nhất định (giọng nói được so sánh) nếu các giọng nói trong hai giọng nói giống nhau hoặc nếu chúng là hai người khác nhau. Tỷ lệ giữa hai xác suất này được gọi là Tỷ lệ khả năng (LR), thường được biểu thị dưới dạng logarit dưới dạng Tỷ lệ khả năng giống nhau (LLR) hoặc được chuyển đổi thành tỷ lệ phần trăm.
![]()
Đánh giá so sánh
Việc so sánh giọng nói trong hai bản ghi âm hoặc các giọng nói thuộc về cùng một người nói được gọi là thử nghiệm mục tiêu. Nếu giọng nói thuộc về hai cá nhân khác nhau, việc so sánh được gọi là thử nghiệm không nhắm mục tiêu.
Trong quá trình so sánh giọng nói, hai loại lỗi có thể xảy ra. Từ chối sai xảy ra khi hệ thống từ chối không chính xác một thử nghiệm mục tiêu, tức là, hệ thống nói rằng các giọng nói khác nhau mặc dù trên thực tế chúng thuộc về cùng một người. Chấp nhận sai là khi hệ thống chấp nhận không chính xác một thử nghiệm không nhắm mục tiêu, tức là hệ thống nói rằng các giọng nói giống nhau, mặc dù chúng thuộc về những người khác nhau.
Một cách đánh giá hiệu suất của hệ thống nhận dạng giọng nói là tính toán sự đánh đổi giữa hai lỗi này có thể được hiển thị trong biểu đồ Trao đổi Lỗi Phát hiện (DET). Bằng cách giảm ngưỡng chấp nhận, chúng ta giảm xác suất từ chối sai, nhưng đồng thời chúng ta tăng xác suất chấp nhận sai.

Trong một hệ thống lý tưởng, chúng ta muốn cả hai lỗi càng nhỏ càng tốt. Hiệu suất tốt hơn được biểu thị trong biểu đồ DET bởi đường màu đỏ gần với điểm gốc hơn (0 ở cả hai trục x và y). Bằng cách đặt đúng ngưỡng chấp nhận, hệ thống có thể được điều chỉnh cho từng trường hợp sử dụng cụ thể. Ví dụ: trong trường hợp mật khẩu bằng giọng nói để xác thực chuyển khoản ngân hàng khi mong muốn bảo mật cao, ngưỡng cũng phải cao. Đối với các cơ quan thực thi pháp luật đang tìm kiếm bất kỳ nghi phạm nào trong một vụ án, tỷ lệ chấp nhận sai cao hơn là việc có thể chấp nhận được để không lọt bất cứ một tội phạm nào.

Điểm hoạt động của hệ thống khi nó tạo ra cùng số lượng chấp nhận sai và từ chối sai được gọi là Tỷ lệ lỗi bằng nhau. Đây là thước đo phổ biến của hiệu năng tổng thể của hệ thống.
Hiệu chuẩn SID
Điểm số thô phải được hiệu chuẩn để cho phép giải thích thống kê chính xác. Ví dụ, trong một hệ thống được hiệu chỉnh tốt, điểm số 1000 có nghĩa là người dùng có thể chắc chắn hơn 1000 lần rằng người nói trong bản ghi bị nghi ngờ là người nghi ngờ chứ không phải người khác. Về mặt kỹ thuật, điều đó cũng có nghĩa là, 1 trong số 1000 giọng đã được phát hiện không chính xác trong bộ phát triển. Một lý do khác để hiệu chuẩn là điểm số không phụ thuộc vào lượng bằng chứng (lượng lời nói), kênh, chất lượng lời nói, v.v … Bước này rất quan trọng đối với việc phát hiện người nói, hoặc thậm chí trong một số trường hợp giám định, vì vậy nó được tích hợp vào công nghệ SID và được thực hiện trong mỗi so sánh giọng nói.
Hiệu chuẩn Tỷ lệ chấp nhận sai (FAR) – phương pháp hiệu chỉnh này điều chỉnh ngưỡng điểm để phát hiện / loại bỏ giọng nói bằng cách loại bỏ ảnh hưởng của độ dài giọng nói và chất lượng âm thanh. Hệ thống có thể được hiệu chỉnh theo Tỷ lệ chấp nhận sai cụ thể (ví dụ: FAR = 1%) cho mỗi giọng nói tham chiếu (kiểu giọng nói). Hiệu chuẩn FAR của người dùng dựa trên một tập hợp các bản ghi phù hợp với trường hợp sử dụng mục tiêu càng sát càng tốt (thiết bị, kênh âm thanh, khoảng cách từ micrô, ngôn ngữ, giới tính, v.v.). Mặc dù hệ thống mạnh mẽ trong các yếu tố như vậy, hiệu chuẩn này sẽ cung cấp kết quả thậm chí tốt hơn và bằng chứng mạnh mẽ hơn. Tuy nhiên, mục đích chính của hiệu chuẩn FAR là đảm bảo hệ thống chỉ tạo ra một lượng Chấp nhận Sai cụ thể (xem bên dưới) với dữ liệu đã cho. Để thực hiện hiệu chỉnh FAR, bạn sẽ cần một bộ hiệu chuẩn với ít nhất 1000 bản ghi từ các giọng duy nhất, chứa ít nhất 60 giây lời nói ròng.
Chuẩn hóa trung bình – bù cho sự khác biệt về kênh, ngôn ngữ, vv Phương pháp này giúp tăng cường kết quả SID. Bộ dữ liệu chuẩn hóa phải chứa ít nhất 100 giọng nói.